Lab 1: Liveness and Readiness Probes
Introduction
If you want to turn your Kubernetes deployments into auto healing wonders you only have to add a few lines of YAML.
The right combination of liveness and readiness probes used with Kubernetes deployments can:
- Enable zero downtime deploys
- Prevent deployment of broken images
- Ensure that failed containers are automatically restarted
Liveness Probes
Liveness probes will attempt to restart a container if it fails and starts to respond to the probe.
Example of a liveness probe that monitors the /health URL on port 3000.
livenessProbe:
httpGet:
path: /health
port: 3000
Readiness Probes
Updating deployments without readiness probes can result in downtime as old Pods are replaced by new pods and traffic might be sent to the Pod that is not ready to process requests yet (for example because the webserver is still initializing).
With readiness probes, Kubernetes will not send traffic to a Pod until the probe is successful.
Example of a readiness probe that monitors the /ready URL on port 3000.
readinessProbe:
httpGet:
path: /ready
port: 3000
Usage
A typical sequence migth look like this:
- Readiness probe fails
- Kubernetes stops sending traffic to the pod
- Liveness probe fails
- Kubernetes restarts the failed container
- Readiness probe succeeds again (hopefully)
- Kubernetes starts sending traffic to the pod again
Additional parameters are available in order to get better control over the triggering of the probes:
readinessProbe:
httpGet:
path: /monitoring/alive
port: 3401
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 15
successThreshold: 1
failureThreshold: 3
initialDelaySeconds: How long to wait before starting to probe after a container starts. For liveness probes this should be longer than the time your app usually takes to start up. Otherwise you might get stuck in a reboot loop.
timeoutSeconds: How long a probe can take to respond before it’s considered a failure.
periodSeconds: How often a probe will be sent. In most cases you can settle for a value between 10 and 20 seconds.
successThreshold: How many successes are needed before the probe is considered a success again
failureThreshold: How many failures are needed before the probe is considered failed
Create a Probe
In this Lab we will create a websphere open-liberty deployment. Openliberty takes some time to initialize, which will allow us to trigger the probes.
We will be using the root URL (/) to check for the probes, which is a quick and dirty solution.
In more advanced scenarios you should code two separate and specific URLs (for example /ready and /health) that check for more elaboreate scenarios, like:
- Is the webserver up and running
- Is the backend (e.g. database reachable)
- …
The example is the following:
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-liberty
namespace: default
...
spec:
...
template:
...
spec:
containers:
- name: open-liberty
image: open-liberty:full
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
path: /
port: 9080
initialDelaySeconds: 5
periodSeconds: 1
successThreshold: 1
failureThreshold: 1
readinessProbe:
httpGet:
path: /
port: 9080
initialDelaySeconds: 0
periodSeconds: 1
successThreshold: 1
failureThreshold: 1
...
As you can see, we will set the initialDelaySeconds way to low and just give it the possibility to fail once (failureThreshold=1) before triggering a failure.
So we will have the readiness probe triggering almost immediately and the liveness probe 5 seconds later (initialDelaySeconds: 5).
-
Now let’s create the deployment
kubectl apply -f ./training/probes/open-liberty-fail.yaml``
Examine what happened
Let’s examine what happened.
-
Run
k9s, select the open-liberty Pod and hitdfor Describe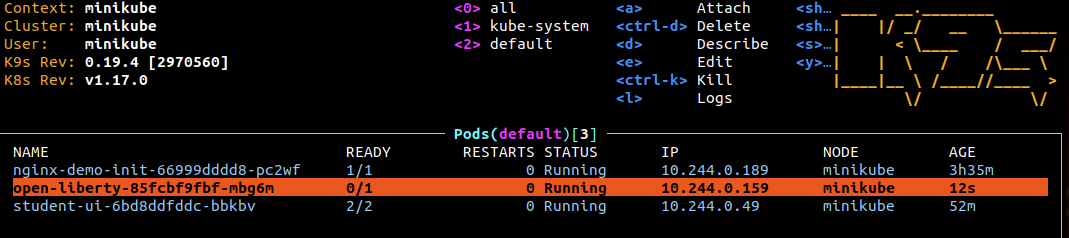
-
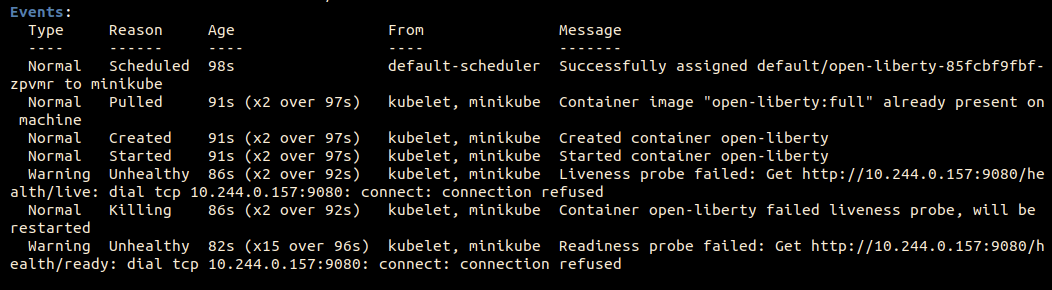
You can see that both probes (readiness and liveness) have been triggered.
The readiness probe checks immediately and allows for only one error before triggering. The liveness probe checks after 5 seconds and allows for only one error before triggering.
-
Run
k9sAfter a while you will see the number of restarts going up and the dreadedCrashLoopBackOffStatus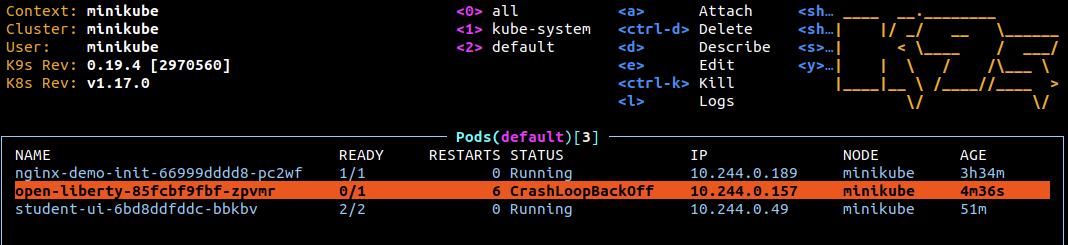
Adapt Probe values
Let’s try to find some more realistic values:
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-liberty
namespace: default
...
spec:
...
template:
...
spec:
containers:
- name: open-liberty
image: open-liberty:full
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
path: /
port: 9080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 1
livenessProbe:
httpGet:
path: /
port: 9080
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 1
...
So with this values for the readiness probe we give the container the time to internally start up the open-liberty server (initialDelaySeconds: 30) - knowing that it takes about 15-20 seconds to initialize - while checking every 10 seconds (periodSeconds: 10).
As for the liveness probe we give the container plenty time to settle (initialDelaySeconds: 60) while checking every 10 seconds (periodSeconds: 10).
- So let’s update the deployment
kubectl apply -f ./training/probes/open-liberty-ok.yaml
Examine what happened
Let’s examine what happened.
-
Run
k9s, select the new open-liberty Pod and hitdfor Describe (the one that says Running)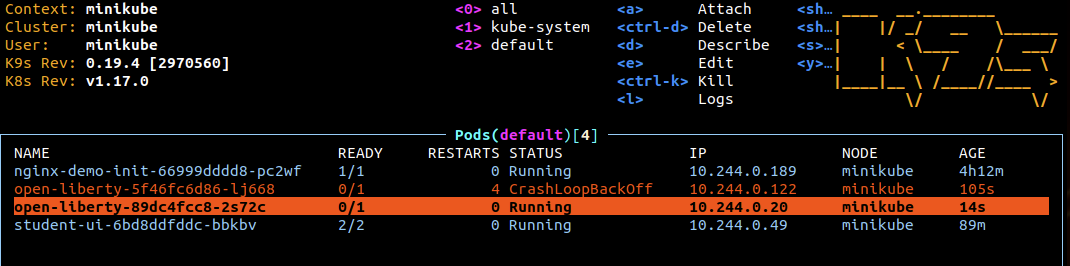
-
You can see that no probe (readiness and liveness) has been triggered.

-
Hit
ESCto go back and you can see that while Kubernetes waits for the new Pod to become available, the old one is kept in placeHere we have to wait for the 30 seconds (initialDelaySeconds=30) until the Pod becomes ready, even if it would be able to already accept requests. So it is very important to finely tune this parameter in order to avoid to much startup-lag.
-
Once the new Pod is ready, the old one is being terminated This mechanism ensures, that existing deployments get deleted only when the new one can take over.
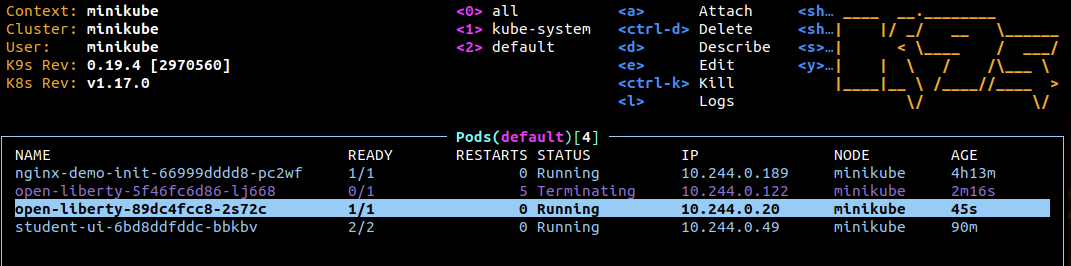
Congratulations!!! This concludes the Lab on Probes